PATAGAMES 博客
如何在 C# 代码中从多个扫描页面创建 PDF
2016 年 4 月 9 日
PDF
评论 (4)
.png)
本教程介绍了如何使用简单的 C# 代码和 PDFium 库从一堆扫描图像组成 PDF 文档。 可能的用途是批量扫描文档、创建电子书、将书籍转换为电子可读格式等。
那么,让我们看看如何使用 PDFium .Net SDK 做到这一点。 以下是您应该遵循的步骤:
1.启用命名空间
要使该库正常工作,您需要在应用程序中包含以下命名空间:
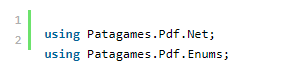
您还需要这些标准的:
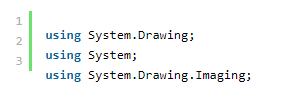
2.初始化库
在你可以使用库的功能之前,你应该初始化它。 要初始化库,请将以下行添加到程序中:

要释放库,请调用:
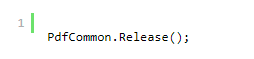
初始化是静态的,这意味着以下内容:
初始化允许对整个进程或 Web 应用程序池使用 PDF 函数。 调用 Initialize() 后,进程的所有线程或应用程序池中的所有 Web 应用程序都将能够使用 PDFium 功能。 初始化是安全的,所以多次调用它是可以的。
但是,最终确定也是静态的。 每当您在一个 Web 应用程序中发布库时,您也会在 Web 应用程序池中的所有其他应用程序中发布该库的所有实例。 因此,在调用Release()之前,你应该确保没有其他Web应用程序或进程的线程仍在使用PDFium。
初始化是线程安全的。你可以从你的应用程序的任何线程中调用它,根本不用担心同步问题。
3.创建一个新的PDF文档
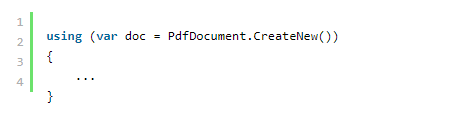
这是代码:

在这里,我们创建了 PdfDocument 类的一个实例。 此对象的静态方法可以采用 PdfForms 参数来启用由 AcroForms 提供支持的交互性。 我们不需要这个选项来从图像创建 PDF,因此我们使用重载的无参数静态方法。
请注意,PdfDocument 对象实现了 IDisposable 接口,因此请确保之后调用 Dispose()。 或者,您可以只使用 using 子句。
到目前为止,这是我们所得到的:

如您所见,一切都很简单。 pageIndex 变量将计算我们文档的页数。
4.扫描和加载图像
现在,我们需要使用刚刚创建的对象将扫描的图像加载到我们的 PDF 文档中。

指定搜索图像的路径、搜索掩码和搜索选项。 上面的代码定位 SourceImages 文件夹和所有子文件夹中的所有图像。
一旦我们获得 files 变量中的文件列表,我们就可以从中获取单个图像:
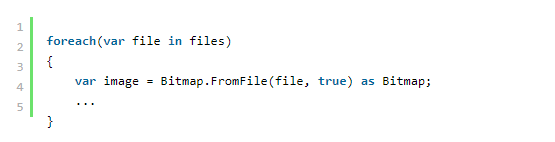
在这里,图像变量是一个位图,但实际格式可能会有所不同。 因此,我们需要使用以下调用将 .Net 图像“标准化”,将其转换为 PdfBitmap 格式:

这里的 CreateBitmap 是一个检测实际图像格式并将其转换为 pdfBitmap 的函数。 函数代码如下:

在这里,我们将 .Net 图像格式转换为 PdfBitmap 格式。 我们在这里所做的只是检测输入图像的 PixelFormat,并创建一个新的 PdfBitmap 对象。 我们还检测图像的调色板(用于索引彩色图像),并在必要时将其应用于输出 PdfBitmap 对象。
请注意我们如何使用 LockBits 方法锁定图像以接收像素数组。 完成工作后不要忘记解锁比特。
要获得图像的实际格式,我们将使用以下函数:

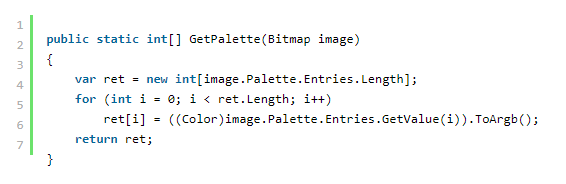
在这个函数中,我们将输入 Bitmap 的像素格式与各种颜色深度格式相匹配。 如果我们没有找到合适的 PDF 格式,我们应该抛出异常。 GetPalette 函数检索图像调色板的 int 值数组。
这是函数:
在调用 CreateBitmap 之后,我们应该创建一个 PdfImageObject,即保存图像并将其呈现在页面上的实际 PDF 对象:

现在所有代码块组装在一起:
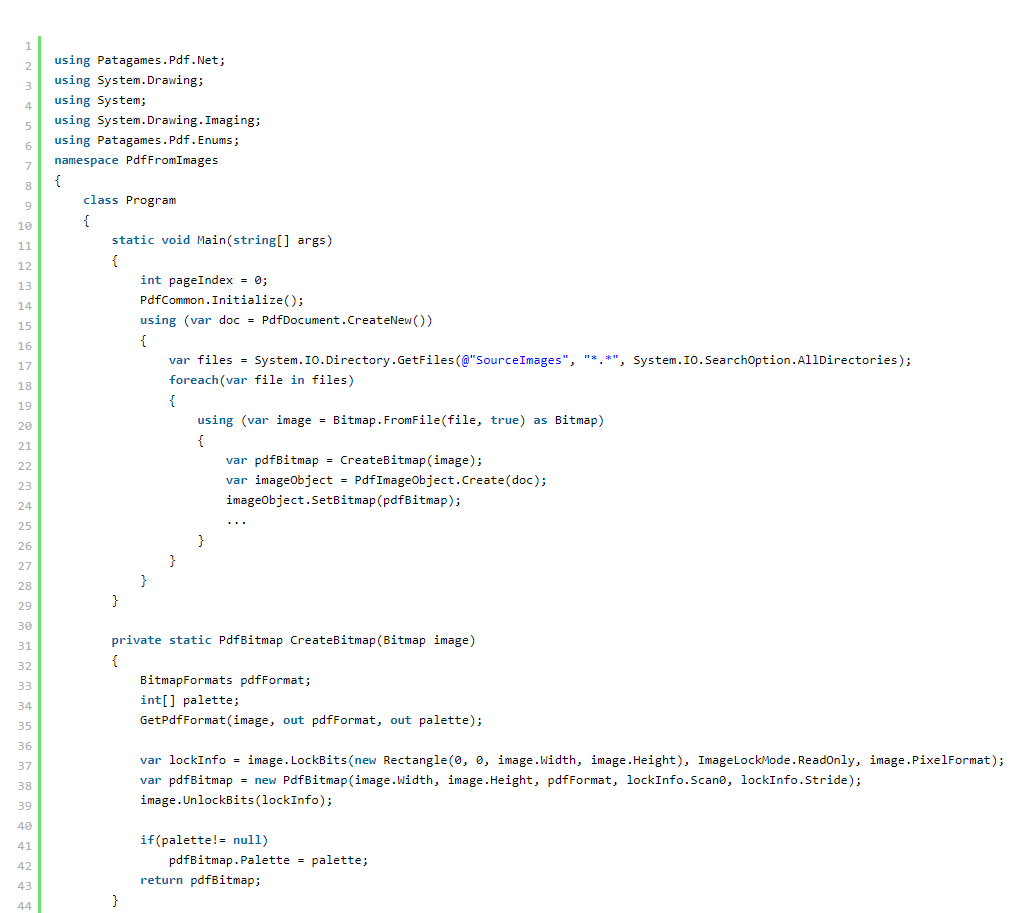
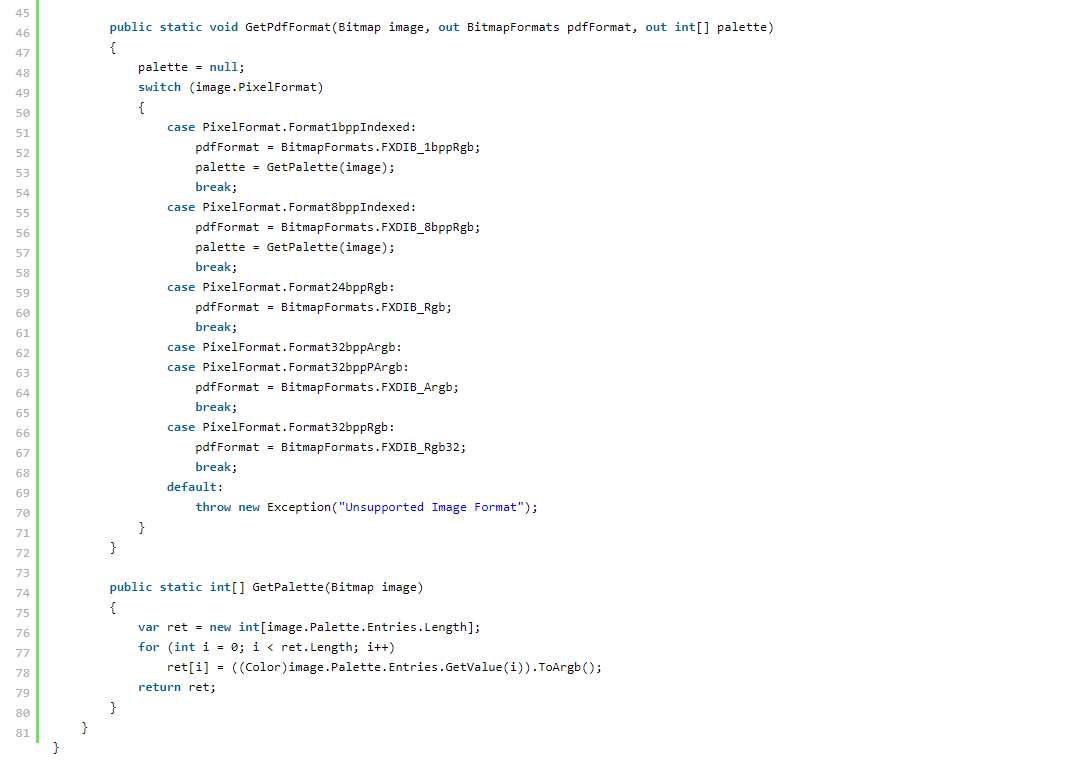
这部分代码的注释:
图片对象也实现了 IDisposable,所以我们需要处理它。 同样,我们将为此使用 using 子句。 PdfImageObject 类的静态方法 Create 将 PdfDocument 变量作为参数,在我们的例子中,这是上面创建的 doc。 图像对象需要文档来创建内部 PDF 字典。
现在对于代码中最重要的部分......
5.计算所需的PDF页面大小
现在我们需要计算页面的大小。 基本上,大小应该等于扫描图像的大小,但诀窍是将图像的像素转换为 PDF 的点。 我们通过调用以下函数来做到这一点:

这是函数本身:
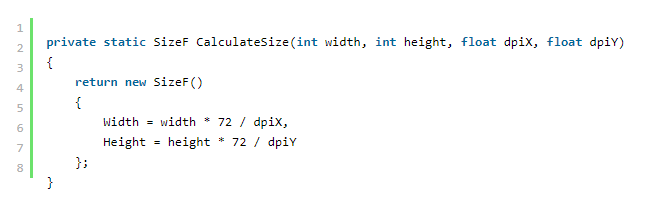
该函数以像素为单位获取位图的宽度和高度以及水平和垂直 DPI,并计算 PDF 页面的大小。 要了解转换,您应该了解以下内容:
- 一英寸正好包含 72 个 PDF 点
- 扫描图像的 DPI 可能非常依赖于扫描分辨率
因此,要将像素转换为印刷点,我们需要将位图的尺寸(以像素为单位)除以该尺寸中的 DPI 值,以获得图像所需的英寸数,然后将该值乘以 72 以找到 PDF 点。 这就是函数的作用。
6.将页面插入PDF文档
我们差不多完成了。 是时候最终将页面插入文档并将转换后的图像插入该页面了。 开始了:

现在,如果您将第 5 步和第 6 步中的最后一段代码组装起来并运行程序,您将得到空的 PDF 页面。 这是为什么? 因为我们没有告诉 PDF 渲染器它应该如何渲染图像。 为此,我们需要为图像对象设置一个变换矩阵。

上面的行告诉渲染器我们希望图像在页面的整个宽度和高度上被拉伸。 然后我们需要将更改应用到页面并使其再次呈现自己:

如果您只需要快速完成工作,请添加这些行并从第 7 步开始继续阅读。但是,如果您想了解转换矩阵的概念,这里有一个简要说明。
理解变换矩阵
如果您几乎不知道什么是矩阵,请务必先在此处阅读我们的矩阵指南。 但是,您不需要这些信息来完成本教程。 您只需要它来了解您可以使用转换矩阵对对象做什么,以及为什么事情会像它们一样工作。
变换矩阵如下所示:
.png)
其中a、b、c、d、e和f是矩阵的系数。 SetMatrix 函数将这六个系数作为参数数组:
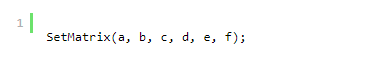
根据我们使用的系数,我们可以通过多种方式变换对象(在我们的例子中为图像):缩放、平移、旋转或剪切。 更具体地说,变换矩阵表示两个坐标系之间的变换:原始坐标系和变换后的坐标系。 在渲染时,图像的每个像素都使用变换矩阵从原始坐标系映射到变换后的坐标系。 这有效地产生了缩放、旋转、平移等图像。
坐标向量和变换矩阵相乘以产生变换后的坐标系——缩放、旋转等。 在我们的例子中,我们希望将图像拉伸到页面的整个大小。 这对应于缩放操作。
这种缩放操作的变换矩阵如下所示:
.png)
所以,我们需要将SetMatrix函数的a参数赋值给size.Width,将d参数赋值给size.Height。 因此代码:

您可以在此处找到有关在 PDF 文档中使用转换矩阵的更多信息。
7. 总结
让我们总结一下到目前为止我们所做的事情。
首先,我们启用命名空间并初始化 PDFium 库。 然后,我们加载要从中创建 PDF 文档的扫描图像。 然后,我们将图像从 .Net 格式标准化为 PDF 兼容格式。 最后,我们计算页面大小并使用转换矩阵将图像一张一张插入,将它们放大到页面的整个大小。
这是最终代码:
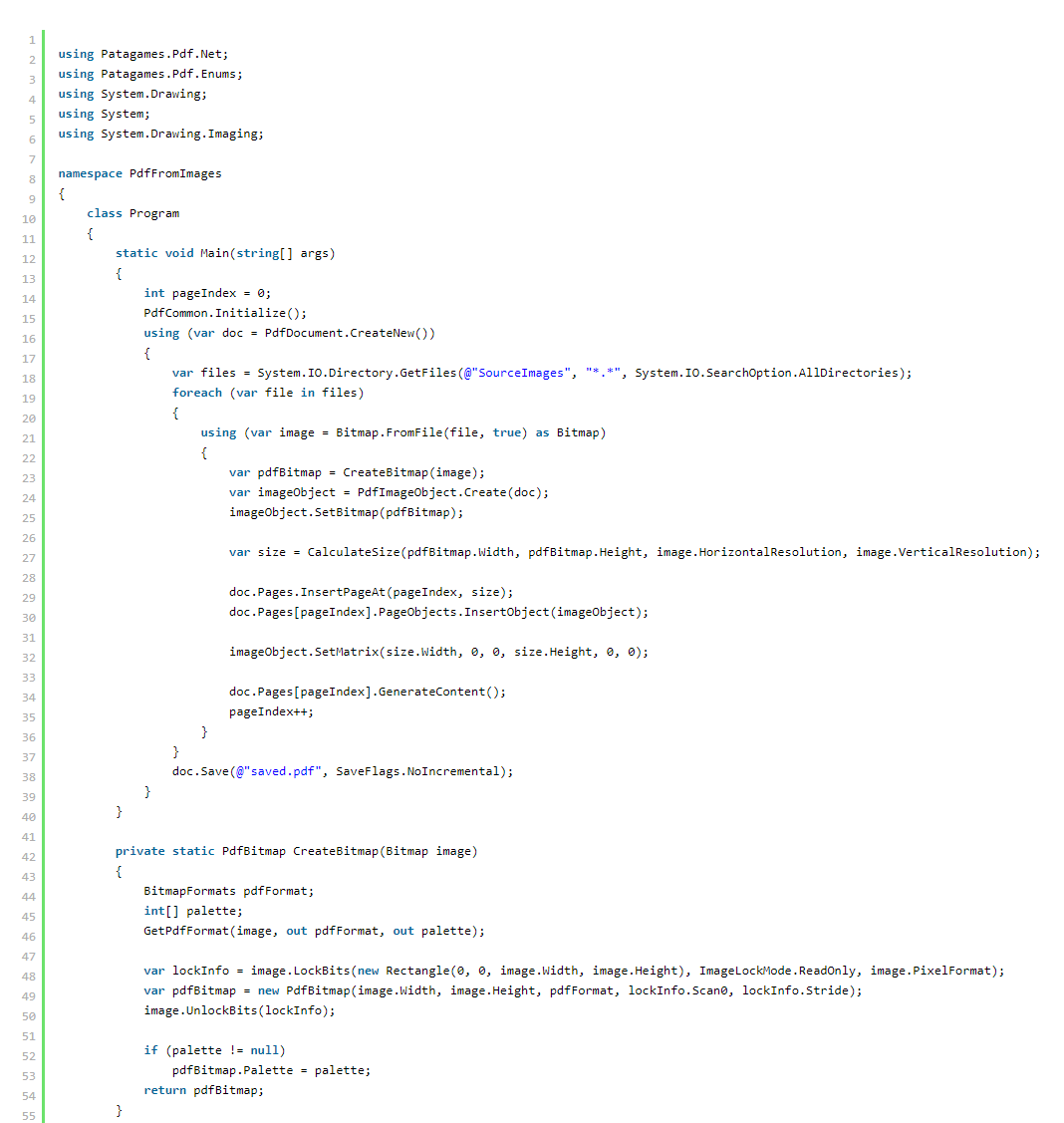
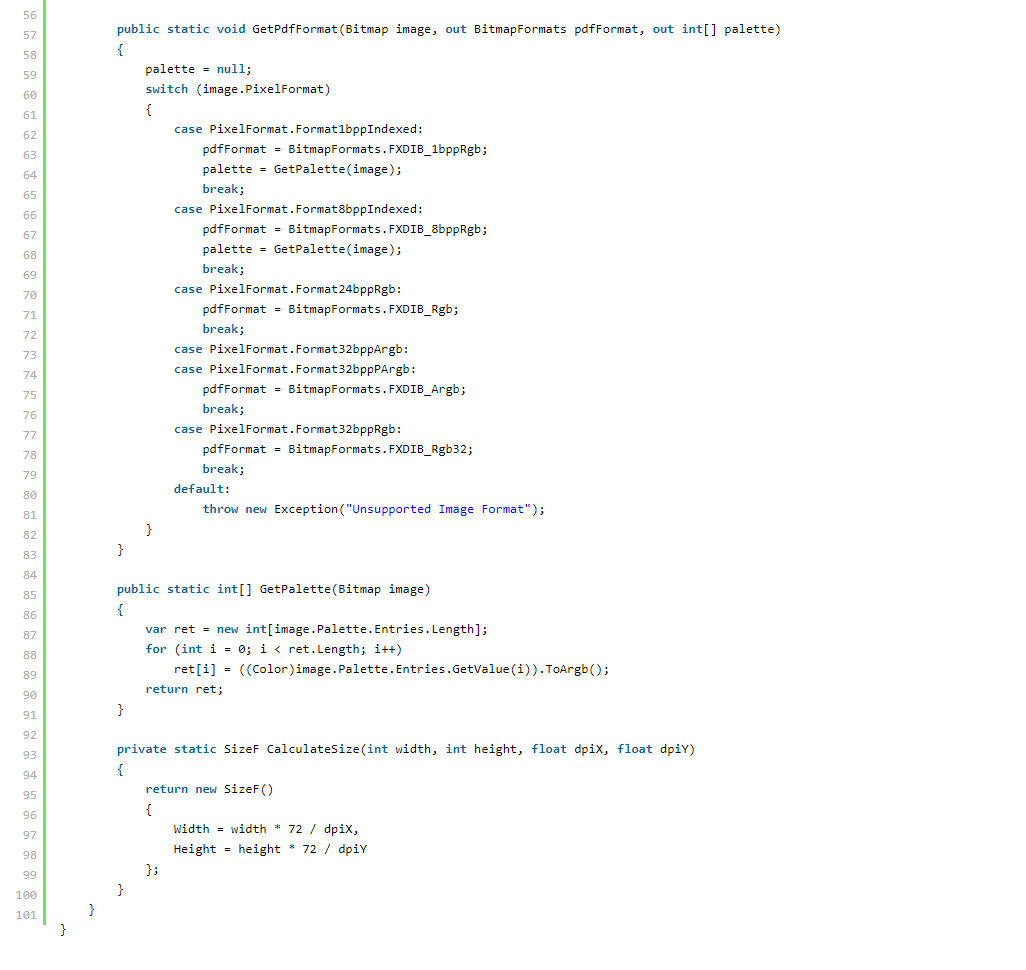
关于最终代码的两条评论。 在第 34 行,我们增加了 pageIndex 计数器。 在第 37 行,我们将最终文档保存为指定的 PDF 文档。
这就是了! 这就是如何使用上述C#代码和PDFium库从扫描的图像阵列中创建一个PDF文档。如果你对本教程有任何疑问,发现错误或想提出建议,请不要犹豫,在下面留下你的评论。
标签: ocr, PDF, 位图, 页面, 渲染器, 光学字符识别, 搜索, 可搜索, 可搜索PDF, Pdfium, 魔方
评论 (6)

jan-Willem de Rijk
2018 年 5 月 27 日下午 7:11:45
你好。
我刚刚购买了您的 OCR SDK 并创建了一个项目。 我对结果 PDF 的质量有点失望。 tekst 似乎有点模糊,字母没有很好的定义。 有没有办法锐化字母并提高输出 PDF 的质量。
提前感谢您的反馈
我刚刚购买了您的 OCR SDK 并创建了一个项目。 我对结果 PDF 的质量有点失望。 tekst 似乎有点模糊,字母没有很好的定义。 有没有办法锐化字母并提高输出 PDF 的质量。
提前感谢您的反馈

Andry
2018 年 5 月 28 日凌晨 2:42:30
你能提供源图像吗?
如需更多帮助,请联系我们。
如需更多帮助,请联系我们。

Sujith Babu
2018 年 10 月 17 日上午 10 点 25 分 59 秒
我的问题是如何从可搜索的 PDF 中搜索特定文本。 您能否提供一些有关如何搜索特定文本及其值的示例代码(例如:“Total:5000”,这里我正在搜索 Total 的值)

Paul Rayman
2018 年 10 月 18 日凌晨 3:10:17
请在此处找到示例
/.../t280-How-to-search-for-a-text-in-a-PDF-file-and-return-the-coordinates-if-the-text-exist
/.../t280-How-to-search-for-a-text-in-a-PDF-file-and-return-the-coordinates-if-the-text-exist
Sujith Babu
2018 年 10 月 18 日上午 5:57:17
谢谢保罗·雷曼。 从我理解的链接中,我们可以搜索 PDF 中的特定文本。 但我的问题是我想找出特定文本的价值。 例如:在 PDF 中,我有“总计:5000”,在这里我正在搜索总计的值。 也就是说,我正在搜索“Total”,它必须返回 5000。
Paul Rayman
2018 年 10 月 18 日下午 1:36:10
在这种情况下,您可以从页面中提取所有文本,然后自己进行搜索。
/.../t3-How-to-Extract-Text-From-PDF-File-in-C
/.../t3-How-to-Extract-Text-From-PDF-File-in-C
COGITO SOFTWARE CO., LIMITED版权所有
