PATAGAMES 博客
如何从扫描的页面制作可搜索的 PDF
2016 年 8 月 2 日
PDF
评论 (0)

扫描的 PDF 文档非常适合阅读,但无法提供除此之外的任何内容。 您无法选择扫描页面上的文本或将某些片段复制到剪贴板。 您无法搜索此类 PDF 文件。 本教程介绍了如何使用 PDFium C# 库和 Tesserat .Net OCR SDK 将扫描的 PDF 转换为可搜索的文档。 要了解如何从扫描的页面创建 PDF,请阅读本教程。
如何工作
这个想法很简单。 我们获取原始 PDF 的扫描页面,使用 OCR(光学字符识别)库对其进行识别,并向 PDF 文件添加一个不可见层,其中包含所有已识别文本以及带有扫描页面的主要可见层。 这允许用户像以前一样查看和阅读文档,但也使他们能够搜索文本、选择文本、将选择复制到剪贴板等。
如何做
1.启用所需的命名空间
要将扫描的 PDF 转换为可搜索的 PDF,我们需要使用以下命名空间:
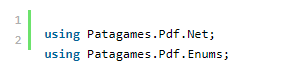
这些是处理 PDF 文档所必需的。

这些提供 OCR 功能。
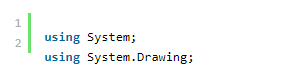
我们还需要一些标准的。
2.初始化库
我们需要初始化 PDFium 库和 Tesseract OCR 库。
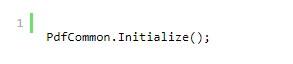
此行初始化 PDFium。 该过程有一些细微差别,因为初始化是静态的。 在此处阅读更多相关信息。
然后我们需要初始化OCR库:
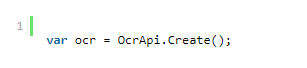
要创建 OcrApi 类的实例,我们调用 Create() 静态方法。 OcrApi 类实现了 IDisposable 接口,因此我们要么需要调用 ocr.Dispose() 要么只需使用 using 子句。 在我们创建了 OcrApi 类的实例之后,我们需要对其进行初始化。 Init() 方法执行此操作。
该方法如下所示:
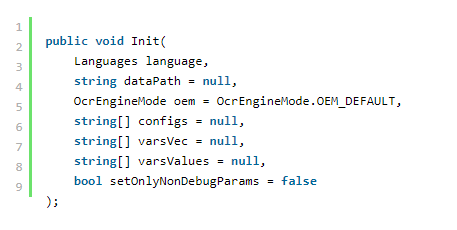
在我们的示例中,我们不需要所有这些参数来将扫描的 PDF 转换为可搜索的 PDF。 事实上,您完全可以不带任何参数调用 Init(见下文)。 但是,其他任务可能需要它们,因此我们在此处简要说明可以传递给 Init 的内容。
语言
此参数指定 OCR 的一种或多种语言。 您可以识别多语言文档,但包含的语言越多,应用程序消耗的内存就越多。 更多的语言也意味着更低的 OCR 质量。 在我们的例子中,我们只使用英语,这也是 OCR 引擎的默认语言。
注意:tessdata 文件夹应包含您在 OCR 中使用的所有语言的数据文件。
dataPath
这是 tessdata 文件夹的父文件夹的路径 - 语言数据文件所在的文件夹。 这可以是完整路径,也可以是相对路径。 路径应以尾部反斜杠结尾。 例如,如果tessdata文件夹的路径是c:\MyApp\tessdata\,那么dataPath参数中传递的路径应该是c: \我的应用程序\。
如果不指定参数,则路径默认为应用的当前文件夹。
注意:如果当前文件夹以某种方式发生变化(例如,当用户在打开或保存对话框中更改当前文件夹时),省略的 dataPath 也将指向这个新位置! 因此,好的做法是在此参数中显式指定路径。
oem
此参数使用以下可用选项指定 OcrEngineMode:OEM_TESSERACT_ONLY 用于最快的 OCR,OEM_CUBE_ONLY 用于较慢但准确的识别,OEM_TESSERACT_CUBE_COMBINED 用于极高的准确度和 OEM_DEFAULT。 后者根据特定于语言的配置、命令行配置或(如果没有)默认为 OEM_TESSERACT_ONLY 中的变量确定 OCR 模式。
注意:tessdata 文件夹应该有相应的语言文件,以便初始化 OCR 模式。 OCR 模式的语言文件名是:
- *.trained – for the OEM_TESSERACT_ONLY mode;
- *.cube.* – for the OEM_CUBE_ONLY mode;
- *.tesseract_cube.* – for the OEM_TESSERACT_CUBE_COMBINED mode.
如果缺少对应的文件,初始化将失败。
配置
配置文件名数组。 相应的配置文件应位于 tessdata 文件夹的 configs 或 tessconfigs 子文件夹中。
varsVec
配置变量名称数组。 这是配置 Tesseract 的另一种方法。
varsValues
配置变量值的数组。 支持的变量列表可见 这里
以这种方式传递的变量比配置文件具有更高的优先级。 这允许您通过使用 varsVec 和 varsValues 参数直接传递相应的变量来覆盖某些设置。
setOnlyNonDebugParams
出于调试目的禁用。 启用最终构建。
目前,我们只使用一个参数并按如下方式初始化 OCR:

所有其他参数都被省略并设置为它们相应的默认值,如上所述。
所以,这里是我们目前得到的 C# 代码:

一旦我们完成了初始化,就该做一些工作了。
3. OCR 页面
要从图像构建 PDF,我们需要一个渲染器。 在我们的例子中,我们需要一个名为 OcrPdfRenderer 的特定渲染器。

在这里,我们告诉静态方法创建文件名以将识别的PDF文件保存为(第一个参数)以及语言数据文件的位置(第二个参数)。 请注意,与上面的初始化过程不同,此方法需要 tessdata 文件夹的路径,而不是父文件夹。
OcrPdfRenderer 类也实现了 IDisposable,所以不要忘记调用 Dispose 或坚持使用,如下所示。
现在我们已经创建了渲染器,我们将扫描的 PDF 文件的页面传递给它。 对于每个页面,我们将其渲染为位图,然后我们识别它并将识别的文本添加到页面中。 这是执行所有这些操作的代码片段:

让我们稍微详细说明一下这段代码。
此行开始一个新文档:

下一行加载我们的源PDF文档,就是那个有扫描图像的文档。PdfDocument对象需要最后的Dispose(),因此再次使用了using子句。

我们要为每个页面创建一个位图,因此我们计算所需的位图宽度和高度(以像素为单位),它是从 PDF 页面的尺寸(以 Points 为单位)转换而来的。 每个点是 1/72 英寸,所以我们基本上取图像的垂直或水平 DPI(在我们的示例中为 96),将其乘以相应的维度并除以 72。
我们的下一行使用我们刚刚计算的尺寸创建了一个新的 PdfBitmap。 构造函数的最后一个参数告诉使用真彩色模式。

然后我们用白色填充整个位图并将页面渲染到它:

最后,完成所有工作的行:

该方法有四个参数:要识别的图像、我们当前不需要的调试配置文件、最大超时(零表示没有超时)和渲染器。
OcrPix 将 .Net 格式的位图作为参数,因此我们只需使用 bitmap.Image 属性传递一个。
这是一个相当长的步骤,但我们收到的实际代码很短。 这是整个程序:
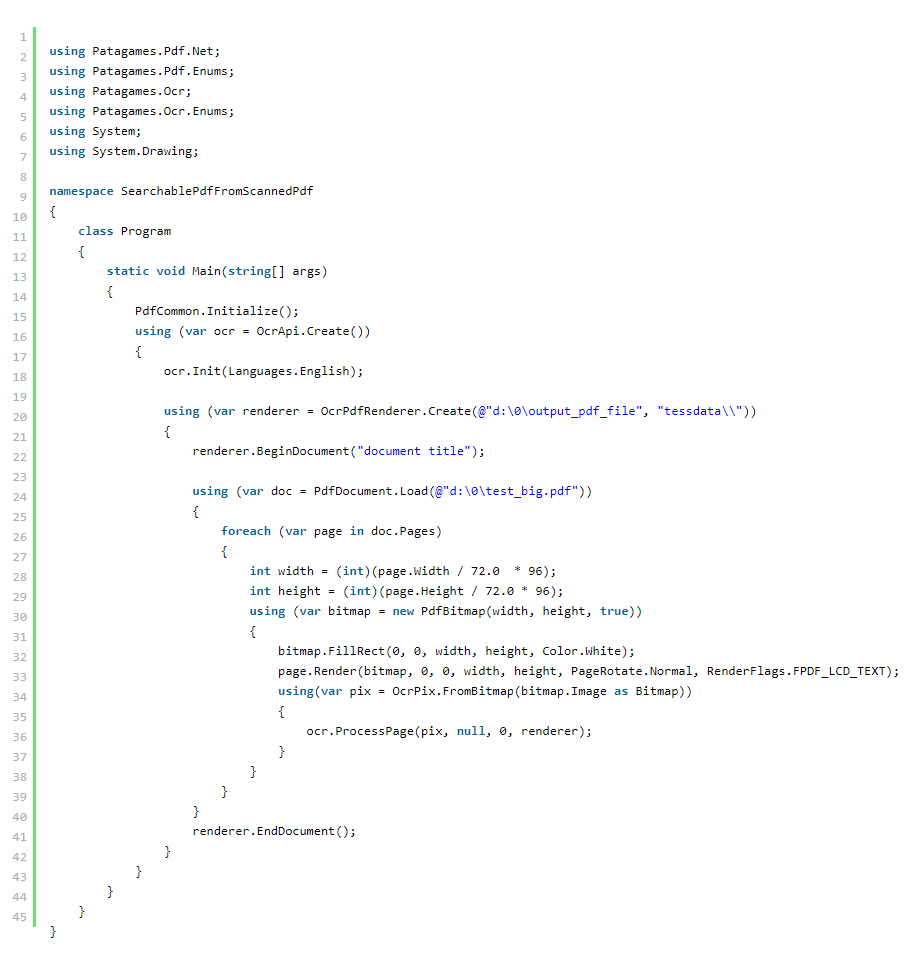
最后的注释
需要调用 EndDocument() 方法来完成 PDF 文档。 另请注意,Tesseract OCR 无法可靠地识别小于 20 像素的符号,因此请确保扫描页面的 DPI 足以提供至少该行高。
标签: ocr、PDF、位图、页面、渲染器、光学字符识别、搜索、可搜索、可搜索 pdf、Pdfium、tesseract
评论 (6)

jan-Willem de Rijk
2018 年 5 月 27 日下午 7:11:45
你好。
我刚刚购买了您的 OCR SDK 并创建了一个项目。 我对结果 PDF 的质量有点失望。 tekst 似乎有点模糊,字母没有很好的定义。 有没有办法锐化字母并提高输出 PDF 的质量。
提前感谢您的反馈
我刚刚购买了您的 OCR SDK 并创建了一个项目。 我对结果 PDF 的质量有点失望。 tekst 似乎有点模糊,字母没有很好的定义。 有没有办法锐化字母并提高输出 PDF 的质量。
提前感谢您的反馈

Andry
2018 年 5 月 28 日凌晨 2:42:30
你能提供源图像吗?
如需更多帮助,请联系我们。
如需更多帮助,请联系我们。

Sujith Babu
2018 年 10 月 17 日上午 10 点 25 分 59 秒
我的问题是如何从可搜索的 PDF 中搜索特定文本。 您能否提供一些有关如何搜索特定文本及其值的示例代码(例如:“Total:5000”,这里我正在搜索 Total 的值)

Paul Rayman
2018 年 10 月 18 日凌晨 3:10:17
请在此处找到示例
/.../t280-How-to-search-for-a-text-in-a-PDF-file-and-return-the-coordinates-if-the-text-exist
/.../t280-How-to-search-for-a-text-in-a-PDF-file-and-return-the-coordinates-if-the-text-exist
Sujith Babu
2018 年 10 月 18 日上午 5:57:17
谢谢保罗·雷曼。 从我理解的链接中,我们可以搜索 PDF 中的特定文本。 但我的问题是我想找出特定文本的价值。 例如:在 PDF 中,我有“总计:5000”,在这里我正在搜索总计的值。 也就是说,我正在搜索“Total”,它必须返回 5000。
Paul Rayman
2018 年 10 月 18 日下午 1:36:10
在这种情况下,您可以从页面中提取所有文本,然后自己进行搜索。
/.../t3-How-to-Extract-Text-From-PDF-File-in-C
/.../t3-How-to-Extract-Text-From-PDF-File-in-C
COGITO SOFTWARE CO., LIMITED版权所有
